
O tidyverse em números
O ecossistema do {tidyverse} cresceu muito nos últimos anos. Em outro post disctiu-se algumas das razões do seu sucesso em maiores detalhes. Em linhas gerais, o tidyverse apresenta atualmente uma sólida combinação de fatores tanto para iniciantes como para usuários experientes.
- Funções consistentes. As funções do
tidyversetem nomes padronizados e funcionam de maneira mais consistente do que as alternativas do Base-R. - Compatibilidade. As funções do
tidyverse - Solução de ponta a ponta.
Explorando o tidyverse
O “núcleo duro”, por assim dizer, do tidyverse é composto por 8 pacotes:
dplyrtidyrtibblereadrstringrlubridateforcatspurrrggplot2
Cada um destes pacotes resolve algum problema central na análise de dados. O pacote readr importa os dados; o tibble é a plataforma que contém os dados; dplyr e tidyr limpam os dados; e, finalmente, ggplot2 visualiza os dados.
Os pacotes lubridate, forcats e stringr lidam com as três classes importantes de dados: datas, factors e texto. Por fim, o pacote purrr amarra todo este ecossistema de pacotes numa abordagem de programação funcional que é elegante e eficiente.
Além dos pacotes core, o tidyverse traz junto consigo outros pacotes importantes como
rvest/xml2/httr, para webscrapping,jsonlite/readxl/haven/feather, para importação de outros tipos de arquivos de dados emodelr/broompara modelagem de dados e apresentação de resultados.
Números do CRAN
Olhando para as estatísticas do CRAN, vê-se que os pacotes do tidyverse são muito relevantes dentro do ecossistema. Os dados compilados abaixo mostram o retrato dos pacotes do CRAN em 05 de setembro de 2023, quando havia cerca de 19.800 pacotes ativos.
Note que nos gráficos abaixo, o ano de publicação reflete o ano da versão mais recente de cada pacote. Assim, pacotes ativos cuja última atualização foi anterior a 2016 dificilmente vão possuir alguma dependência com os pacotes do tidyverse já que a maioria deles estava ainda na sua infância.

A presença de pacotes do tidyverse é crescente, chegando a mais de 40% em 2023.
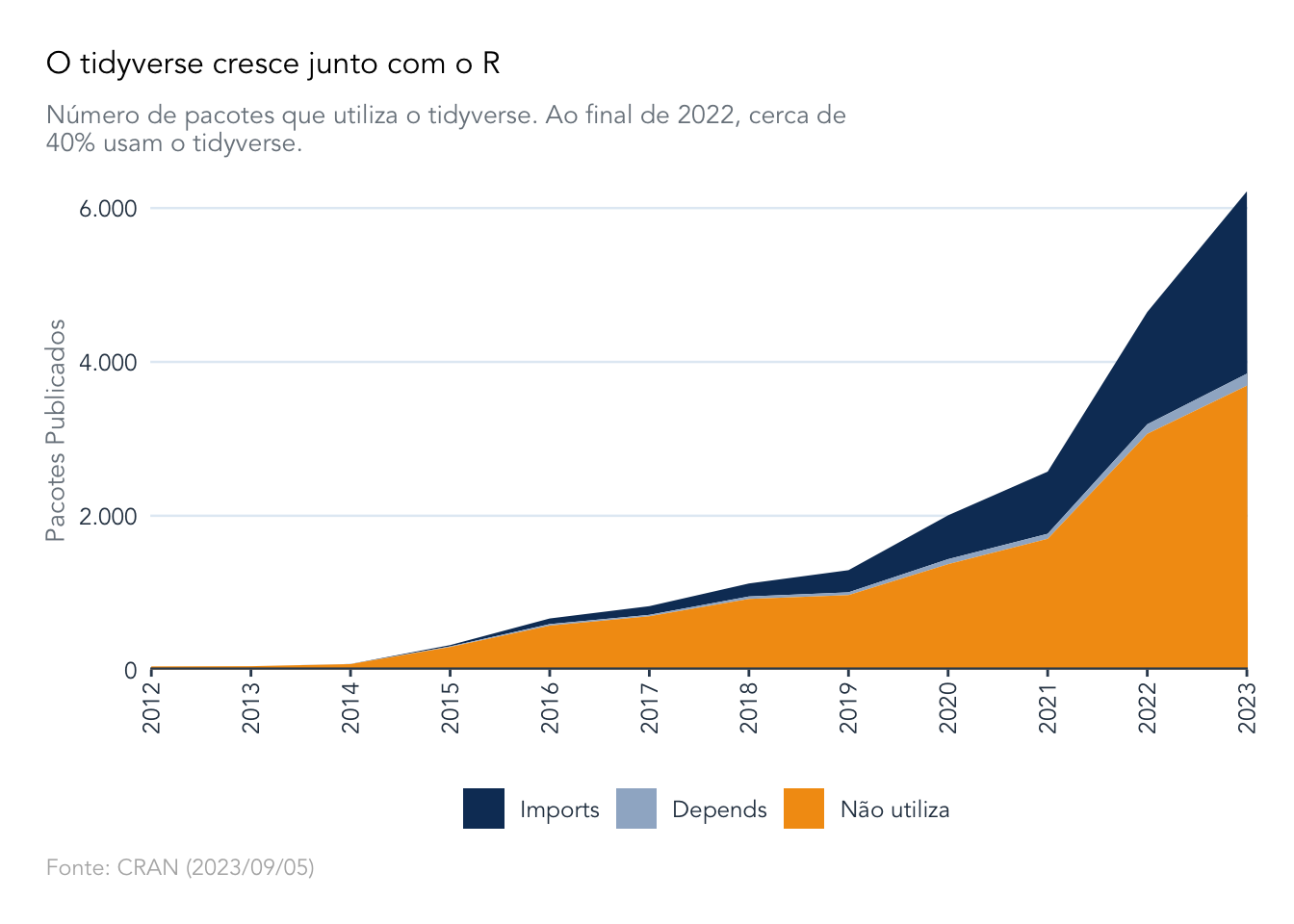
Vale lembrar que há três tipos de “dependência” entre pacotes no R: imports, depends e suggests. Tipicamente, se um pacote A usa algumas funções de outro pacote B, então o pacote A importa (imports) o pacote B. Isto é, ele assume que o usuário tenha o pacote B instalado. Já a relação depends é mais estrita: se um pacote A depends de um pacote C então os pacotes são carregados conjuntamente quando se chama library()1. Por fim se um pacote A usa um pacote D, em algum contexto específico, mas não requer que o usuário tenha o pacote D instalado, então o pacote A suggests o pacote D2.
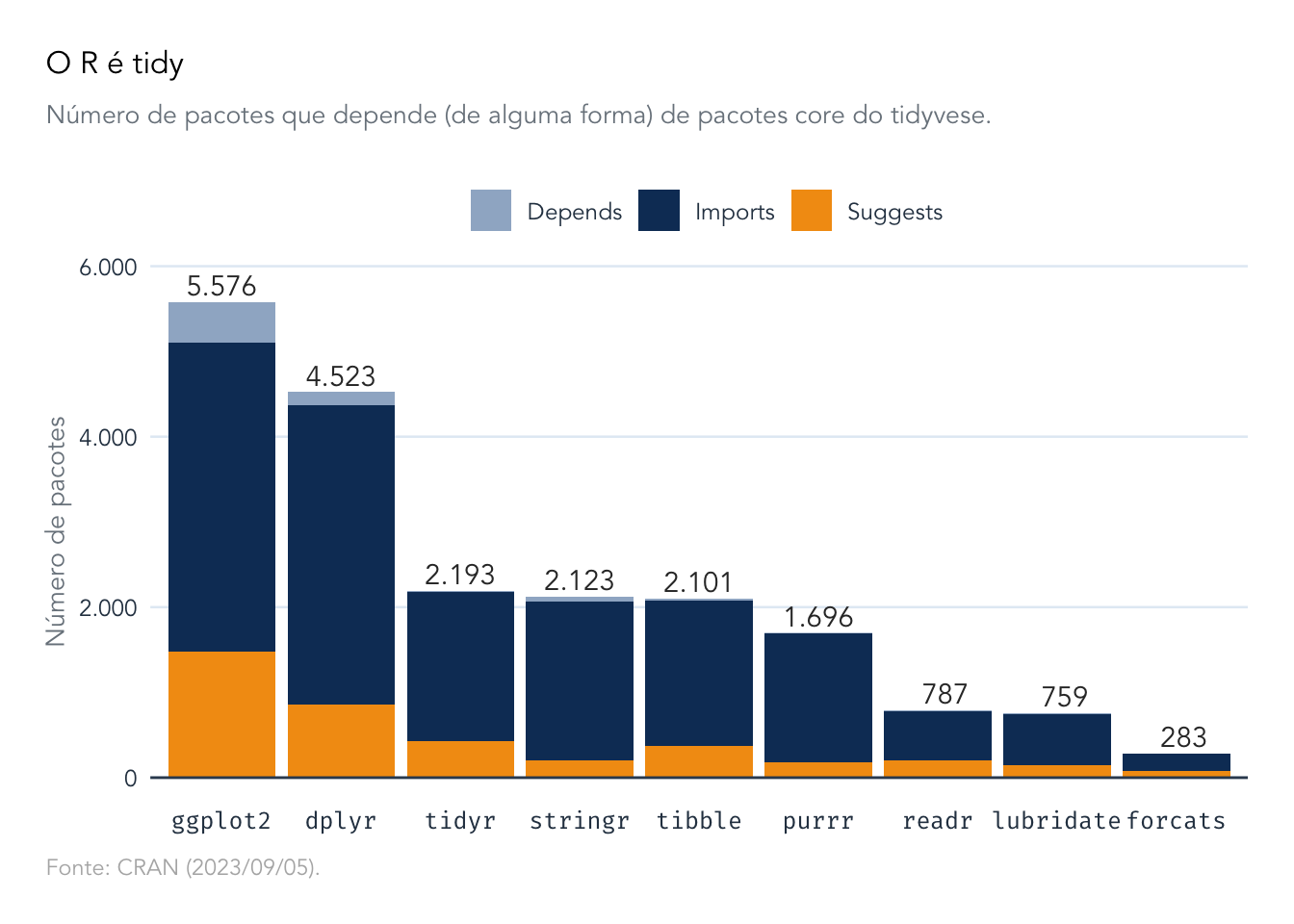
Olhando os dados por pacote vê-se que o ggplot2 e dplyr são os mais populares.
Conclusões dos dados
Os números apresentados confirmam o que muitos já suspeitavam: o tidyverse realmente domina o ecossistema atual do R. Algumas conclusões importantes:
Dominância consolidada
- Mais de 1 em cada 3 pacotes no CRAN dependem de algum pacote do tidyverse
- Entre os pacotes publicados recentemente, essa proporção chega a 40%
ggplot2edplyrlideram como os pacotes mais utilizados como dependências
Crescimento consistente
O crescimento não foi um fenômeno pontual, mas uma tendência consistente ao longo dos anos. Isso sugere que:
- A adoção do tidyverse continua crescendo
- Novos desenvolveurs preferem a abordagem tidyverse
- A comunidade como um todo está convergindo para essa filosofia
Implicações práticas
Estes dados têm implicações importantes para quem está aprendendo R.
Comunidade: uma fatia significativa dos pacotes espera que você conheça o tidyverse.
Relevância no mercado: conhecer o tidyverse se torna cada vez mais sinônimo de conhecer “R”. Vagas ou trabalhos que exigem conhecimento de R implicitamente assumem conhecimento de tidyverse.
Relevância no mercado: Conhecer tidyverse não é mais opcional - é essencial
Compatibilidade: a maioria dos pacotes novos já espera que você conheça tidyverse
Comunidade: você estará falando a “língua” da maioria da comunidade R atual
Uma ressalva importante
Números altos não significam necessariamente que tidyverse é “melhor” - apenas que é mais popular. Como discutimos nos posts anteriores da série, tanto tidyverse quanto base-R têm seu lugar no ecossistema.
Posts Relacionados
Mini-cursos relacionados
Para iniciantes:
Gostou do post? Compartilhe com outros que estão aprendendo R e deixe seus comentários sobre quais tópicos gostaria de ver abordados nas próximas séries!
Footnotes
O pacote
ggforce, por exemplo, depends doggplot2. Isto significa quelibrary(ggforce)automaticamente carrega o pacoteggplot2.↩︎Em geral, os pacotes sugeridos (suggests) são listados para os desenvolvedores do pacote ou utilizados para testes e exemplos. Você provavelmente já deve ter visto algum exemplo que começa com:
if (require("pacote")) { … }. O pacotennet, por exemplo, não depende nem importa outros pacotes, mas utiliza o pacoteMASSem seus exemplos; assim, o pacotennetsuggests o pacoteMASS. Também existem casos onde um pacote tem mais capacidades ou melhor performance quando os pacotes sugeridos estão instalados; nestes casos, recomenda-se instalar o pacote cominstall.packages(dependencies = TRUE)`.↩︎